 U+1F4A9 'Pile Of Poo'
U+1F4A9 'Pile Of Poo'
Unicode is one of the greatest standards of the modern age, but its simple appearance hides an insane level of complexity.
Unicode aims to represent every possible character in every possible language in a single character encoding. It’s an ambitious undertaking, the current version has mapped 113 thousand distinct characters to code points in Unicode - each one of which is given a unique name and description.
Basically every language ever written can be encoded with Unicode now. Even dead languages like Phoenician, Aramaic and the Ancient Greek ‘Linear A’ script all have code points assigned. Linear A hasn’t even been deciphered yet, so there are characters in Unicode that no-one knows what they actually represent!
Likewise Unicode contains a huge assortment of symbols that aren’t part of any language. Emoji like a Christmas Tree, a Slice of Pizza, or a Pile of Poop all can be represented with a single Unicode code point.
However, the real craziness with Unicode isn’t in the sheer number of characters that have been assigned. The real fun starts when you look at how all these characters interact with one another.
Deceptively Complicated
Things that seem like they should be very simple are often deceptively complicated when dealing with Unicode strings.
As an example, what would you expect this Python code to print out?
print unichr(0x61b) + " what does this print out ?!?"
I was just going to cut and paste the output there, but the formatting got all messed up, and editing the actual string is kind of impossible (because Unicode). So here’s a screenshot of how this appears on my system:

The real question here isn’t even why the colon prints out last (U+61B is an Arabic Colon, and Arabic has a right to left reading order) - but how come the question marks print out first.
The answer is specified in this seventeen thousand word document on laying out text containing RTL languages. All Unicode characters have a bidirectional character ordering that affects how the text is displayed. The initial arabic character sets the text to read from right to left, causing the question marks to print out first since they are at the end of the string and have a ‘Neutral’ character ordering. The letter ‘t’ has a left-to-right ordering, so when it is printed out it switches the order back - and you get what is displayed above.
This order can of course be completely changed by replacing the Arabic Colon with the Right to Left Override Character (U+202E):

Another good example of Unicode’s hidden complexity is in sorting Unicode strings. Different languages expect different sort orders, and since Unicode aims to encode every possible language - this means sorting strings in a way that people will accept is a relatively difficult undertaking. The relevant document describing how to properly sort strings like this is twenty seven thousand words long, explaining in excruciating detail just how difficult this actually is.
 Relevant XKCD
Relevant XKCD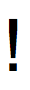 U+1C3 'Latin Letter Retroflex Click'
U+1C3 'Latin Letter Retroflex Click'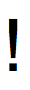 U+21 'Exclamation Mark'
U+21 'Exclamation Mark'Redundant Codepoints
Unicode also has lots of different characters that are visually identical to one another. As an example, the letter ‘V’ and the Roman Numeral Five character (U+2164) look identical in most fonts.
To investigate how widespread this phenomena is, I wrote a little python script to calculate the visual distance between all characters in a font. This script renders each character as a bitmap, treat this bitmap as a set of pixels, and then calculates the Hamming Distance between all the possible sets.
I ran this on the ‘Arial Unicode’ font on my laptop and found that 1831 characters have an exact duplicate and 3158 characters differ by one or fewer pixels.
Now you could argue that there are semantic differences between these characters, even if there aren’t lexical differences. An Exclamation Mark (U+21) and a Retroflex Click (U+1C3) look identical but mean very different things - in that only one of the characters is punctuation. My view is that we shouldn’t be aiming to encode semantic differences at the lexical level: there are words that are spelled the same that have different meanings, so I don’t see the need for characters that are drawn the same to have different encodings. However, I recognize that there are other valid reasons to include these duplicate code points.
Combining Characters
Combining Characters provide yet another way to use different unicode sequences to display the same output. Instead of using the “á” character (U+E1), you can also specify a normal lower case “a” followed by a Combining Acute Accent (U+301) character to display the exact same thing.
Of course there is no reason why you can’t specify that you want 10 accents over the ‘a’ too:
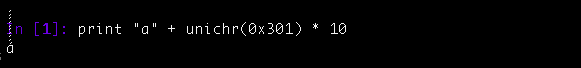
While all the accents are displayed, it looks incorrect because they are overlapping with the text above. The glitchr_ twitter account exploits this issue to break out of the confines of the normal twitter UI.
The presence of combining characters also mean that many common implementations of functions that deal with unicode strings are broken. For example, a typical function to reverse a string might look something like this in Python:
def reverse_string(input):
return ''.join(reversed(input))
This looks correct but produces incorrect output when run on input containing combining characters. Even though the inputs look identical here, the accent shifts position on the second call:

This problem is typically given as a FizzBuzz level interview question for programmers, but I seriously doubt anyone has ever given a solution in an interview that handles unicode strings properly. The esrever library has a correct implementation in Javascript if you’re interested in viewing how to do this correctly.
Another issue that Combining Characters cause is that comparing two Unicode strings to see if they are equal isn’t as simple as comparing the bytes of the strings. Instead you first have to do a Unicode normalization to convert the strings into comparable forms as described in this twelve thousand word specification.
Security Concerns
It’s pretty easy to have two different Unicode strings display identical output - and that can cause a whole host of problems. For instance, many family friendly sites may ban foul language from user comments, but it’s trivial to come up with Unicode equivalent strings that bypass any blacklist of obscene language.
Just for kicks, I wrote a little tool that does exactly that. It randomly reverses bits of the string, but uses the RTL override character to display those reversed bits normally. It also substitutes a bunch of latin characters for their identical Cyrillic or Roman Numeral equivalent. The end result is text that displays normally, but has a representation that is totally divorced from what it displays:
While this seems fairly innocuous, the RTL override character has been used to cloak malicious executables before. There are a lot of other security implications to Unicode spoofing, this sixteen thousand word report has a good breakdown of the basics.
Crazy Complicated - but in a Good Way
My point here is only that even seemingly simple things can be insanely complicated when you dig deep enough. I’m definitely not saying you shouldn’t be using Unicode. In fact, if your code isn’t using Unicode to represent strings right now, you’re almost certainly doing it wrong.
Every change to Unicode has been a rational change by intelligent hard working people. While I can make fun of the poop emoji being included in the Unicode standard, it was the end result of a smart strategic decision by engineers at Google. Now that emoji are included in the Unicode standard, we have the rational follow on decision of supporting racial hints for people in emoji. Likewise by supporting emoji like a piece of pizza, the Unicode consortium has to now make the tough calls on including hot dogs and tacos in the next version of the standard while also excluding hoagies. Even having visually identical characters with different code points was a deliberate design decision - it’s necessary for lossless conversion to and from legacy character encodings.
Unicode is crazy complicated, but that is because of the crazy ambition it has in representing all of human language, not because of any deficiency in the standard itself. Human language is a complicated messy business, and Unicode has to be equally complicated to represent it. Thankfully we have people writing those long standards on how to display bidirectional strings appropriately, or sort strings, or the security implications of all this - so that the rest of us don’t have to think about it and just use standard library code to handle instead.
Code for this post is up on my github.
Published on 26 May 2015
Get new posts by email!
Enter your email address to get an email whenever I write a new post: