As part of my post on matrix factorization, I released a fast Python version of the Implicit Alternating Least Squares matrix factorization algorithm that is frequently used to recommend items. While this matrix factorization code was already extremely fast, it still wasn’t implementing the fastest algorithm I know about for doing this matrix factorization.
This post is just a quick follow up, talking about why this algorithm is important, where the common solution is slow and how to massively speed up training using a paper based on using the Conjugate Gradient method.
Implicit Matrix Factorization
"Trick for productionizing research: read current 3-5 pubs and note the stupid simple thing they all claim to beat, implement that." Jay Kreps
The algorithm described in Collaborative Filtering for Implicit Feedback Datasets is one of those stupid simple approaches that is extremely scalable and still produces decent recommendations.
Since this approach scales pretty well, the implicit recommendation module in Spark mllib uses this algorithm. Even Facebook admits to using this algorithm for doing implicit recommendations in their post Recommending items to more than a billion people.
In my last post on matrix factorization I tried to show how this algorithm generalized a dataset of music plays from last.fm. The cool result was that this algorithm learned that bands labelled ‘Arcade Fire’ and ‘The Arcade Fire’ are in fact very similar (since its just different a spelling of the same band) - even though no users in the dataset listened to both:
The algorithm works by calculating user factors \(X_u\) directly from the item factors \(Y\) by solving:
$$X_u = (Y^TC_{u}Y + \lambda I)^{-1}(Y^TC_UP_u) $$
Where \(C_u\) is a vector of the confidence we have that the user liked each item, and \(P_u\) is a binary preference of whether the user listened to the artist. The item factors are constructed in the same way, and the algorithm iterates between calculating the item factors and the user factors until it converges.
The slow part of calculating this is in dealing with the \(Y^TC_uY + \lambda I\) term . When computing with N factors - constructing this matrix is O(N2) with respect to the number of non-zero items. Solving this equation is also O(N3) and has to be done for every user. Depending on the sparsity of the matrix and the number of factors either one of these of those might dominate the run time.
Speeding this up with the Conjugate Gradient Method
The Applications of the Conjugate Gradient Method for Implicit Feedback Collaborative Filtering paper shows how to speed this up by orders of magnitude by reducing the cost per non-zero item to O(N) and the cost per user to O(N^2).
The Conjugate Gradient method is an iterative approach to solving a system of linear equations. Since we have a nice quadratic loss function, the gradient is a linear function - and to minimize this we just have to solve that function for when the gradient is zero. My post on Numerical Optimization had an interactive demo of how the Nonlinear Conjugate Gradient Method worked - and I thought I’d adapt it here to show how the Linear Conjugate Gradient method works. The red path below is the search direction taken, and the yellow arrow is the gradient at each iteration:
\(=\)
\(.26 (x^2 + y^2) + .48 x y \)
The Conjugate Gradient method can minimize any 2D quadratic function in only two iterations - no matter the starting point (click to pick a new point). Unlike the Nonlinear Conjugate Gradient Method, it also doesn’t have to mess around with doing a line search to find the appropriate step size, since the exact best step size can be computed directly.
In applying the conjugate gradient method to our matrix factorization problem, the idea is to avoid solving \(X_u = (Y^TC_uY + \lambda I)^{-1} Y^tC_uP_u\) exactly on each iteration. This result is expensive to compute, and will just be overwritten on the next alternating least squares iteration. Instead of solving, we take a couple conjugate gradient steps towards the solution, using the previous value as the starting point.
The cool thing here is that we don't even need to build up the \(Y^TC_uY + \lambda I\) matrix in this case, let alone solve it. All that's needed is multiply this matrix by the current search direction - which can be done here without materializing this matrix for each user by using the same trick as in the original paper, by noting that \(Y^TC_uY = Y^TY + Y^T(C_U - I)Y\) and precomputing the \(Y^TY\) matrix for all users.
The complete implementation in Python for this algorithm is:
def alternating_least_squares_cg(Cui, factors, regularization=0.01, iterations=15):
users, items = Cui.shape
# initialize factors randomly
X = np.random.rand(users, factors) * 0.01
Y = np.random.rand(items, factors) * 0.01
Cui, Ciu = Cui.tocsr(), Cui.T.tocsr()
for iteration in range(iterations):
least_squares_cg(Cui, X, Y, regularization)
least_squares_cg(Ciu, Y, X, regularization)
return X, Y
def least_squares_cg(Cui, X, Y, regularization, cg_steps=3):
users, factors = X.shape
YtY = Y.T.dot(Y) + regularization * np.eye(factors)
for u in range(users):
# start from previous iteration
x = X[u]
# calculate residual r = (YtCuPu - (YtCuY.dot(Xu), without computing YtCuY
r = -YtY.dot(x)
for i, confidence in nonzeros(Cui, u):
r += (confidence - (confidence - 1) * Y[i].dot(x)) * Y[i]
p = r.copy()
rsold = r.dot(r)
for it in range(cg_steps):
# calculate Ap = YtCuYp - without actually calculating YtCuY
Ap = YtY.dot(p)
for i, confidence in nonzeros(Cui, u):
Ap += (confidence - 1) * Y[i].dot(p) * Y[i]
# standard CG update
alpha = rsold / p.dot(Ap)
x += alpha * p
r -= alpha * Ap
rsnew = r.dot(r)
p = r + (rsnew / rsold) * p
rsold = rsnew
X[u] = x
To make this algorithm run fast, I’ve also added a Cython implementation that uses OpenMP to parallelize computation - and uses direct BLAS calls. All the benchmarks here are against that version.
Measuring the Speed and Accuracy of this code
While I love a good application of the Conjugate Gradient method as much as anyone, it doesn’t really matter how fast this method is if the results aren’t as good.
To test out the accuracy, I’m just computing the training loss at each iteration and comparing to my original implementation that uses a Cholesky solver to get an exact solution at each iteration. Since we’re just comparing optimization methods on the same loss function, training loss is sufficient to prove that each method is actually converging. Running this on the last.fm dataset with 100 factors shows:
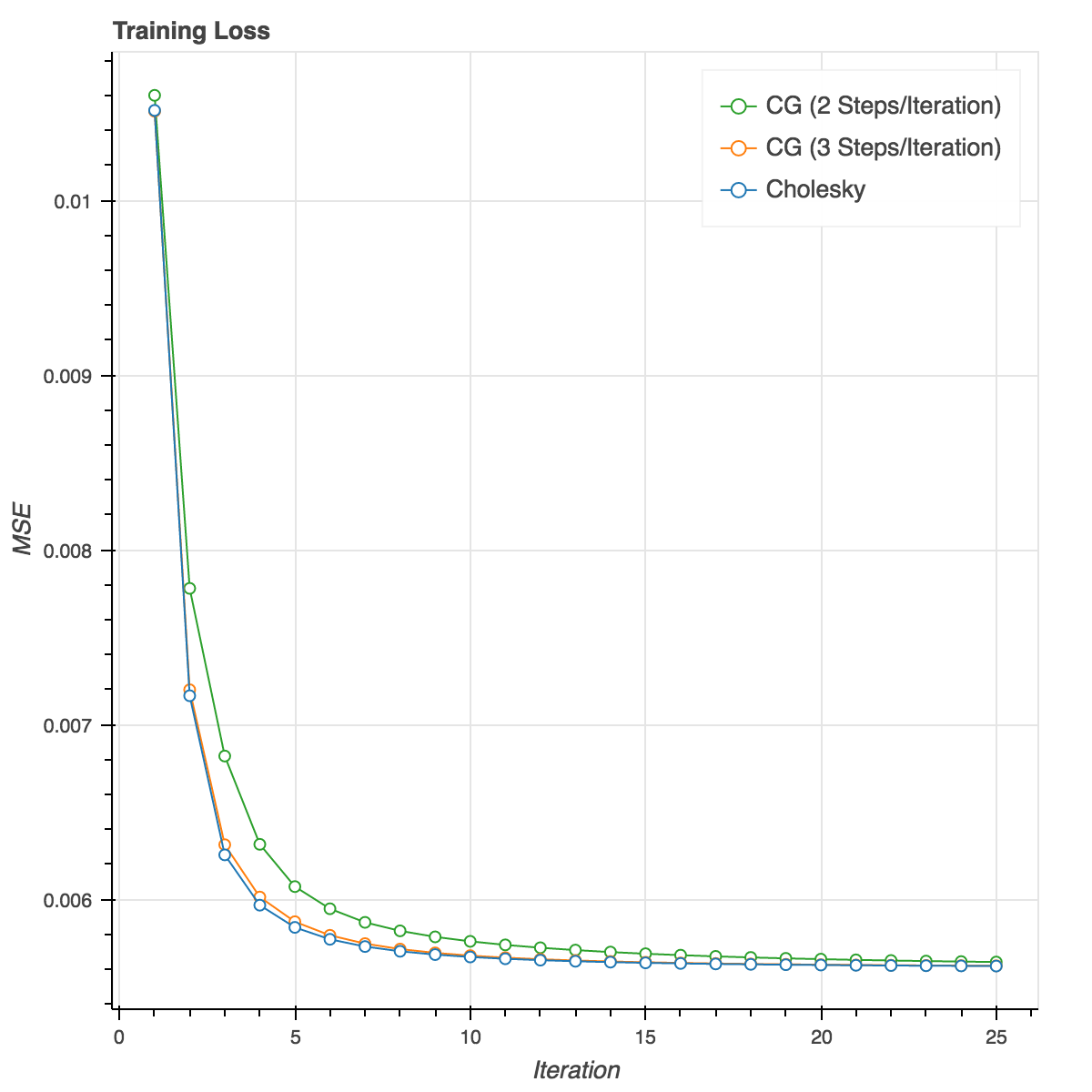
The paper suggests using 2 Conjugate Gradient steps at each iteration, but I found that using 3 leads to results that are more directly comparable to the original version. In fact after 10 iterations or so the loss is basically identical to the Cholesky solver.
Finally, all this effort is for nothing if the code isn’t actually faster to run. Benchmarking the time per iteration on my laptop shows a pretty big speed increase as the number of factors grows:
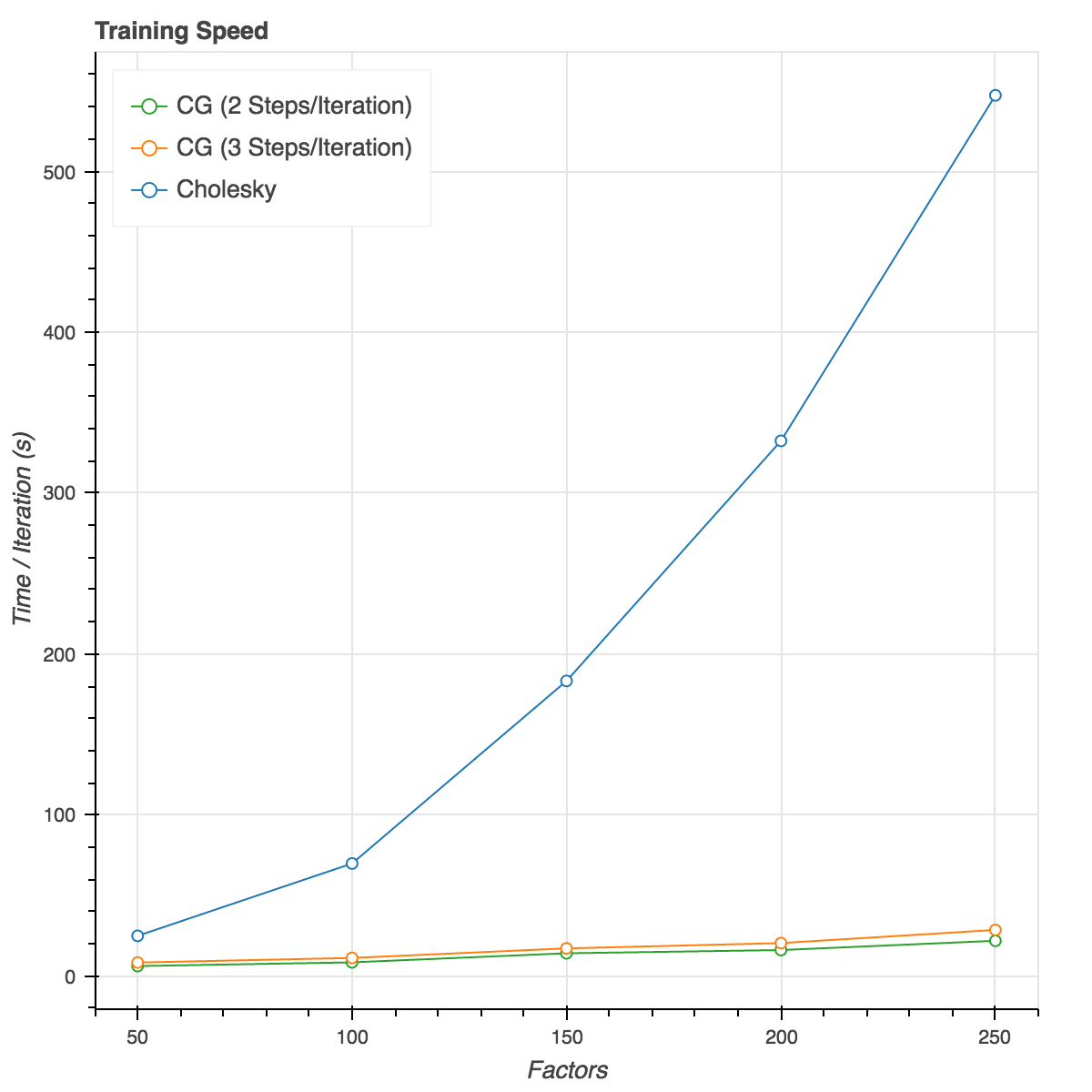
With 3 Conjugate Gradient steps per iteration, this code is 3 times as fast with 50 factors and 19 times as fast with 250 factors. All told that’s a pretty nice speed bump for a relatively small and straightforward change to the code.
I’ve updated my implicit recommendations library to use this method by default - and pushed the test script to benchmark this there as well. I’ve also add the linear conjugate gradient example to my javascript numerical optimization library.
Published on 12 December 2016
Get new posts by email!
Enter your email address to get an email whenever I write a new post: